Integración Replicante: caso Snowflake, cuando el ORM no existe y los callbacks resisten

Contenido
Capítulo 1: Un novato en las calles de la consultora
Era un día cualquiera de lluvia ácida en la ciudad de Neovaldivia. Por alguna razón siempre llueve cuando recibes tu primer caso.
Acababa de llegar a la consultora. Todavía no terminaba de acomodar mi escritorio virtual cuando me asignaron un cliente nuevo: una corporación a la que llamaremos Wallace Corp para mantener su privacidad (y yo mi trabajo), me comentó que tenía datos valiosos almacenados en un lugar al que muy pocos sabían cómo acceder.
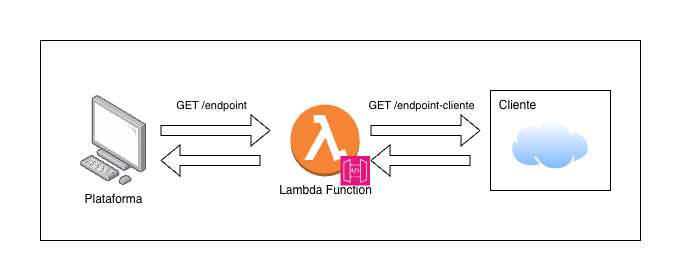
La solicitud era simple, casi demasiado para ser real: "Necesitamos un scheduler que se ejecute una vez al día. Debe consultar nuestra base de datos, extraer toda la información y enviarla a la plataforma. Nosotros les daremos un endpoint para que hagan un GET y listo."
Un GET diario. Transformar data. Cargarla en la plataforma. Un caso estándar de ETL que cualquier Blade Runner con dos líneas de código podría resolver antes del almuerzo. O eso parecía.
Me serví un café instantáneo cargado, abrí el editor y esperé a que llegaran las credenciales del endpoint.
Lo que llegó fue otra cosa.
Capítulo 2: Nieve en la ciudad, el endpoint que nunca existió
En lugar de recibir una URL limpia, y si tenía suerte, con documentación Swagger y ejemplos de respuesta, Wallace Corp nos entregó un sobre digital con algo que no esperaba: credenciales de acceso directo a una base de datos Snowflake.
No había endpoint. No había API. No había capa de abstracción. Solo un account, un username, un password y el nombre de un warehouse esperando al otro lado de la línea.
Nunca había trabajado con Snowflake, es más, ni siquiera sabía de su existencia. En esa época no existía la IA para preguntarle qué hacer; no había ningún Claude ni ChatGPT esperando en una pestaña del navegador. Solo estábamos Google, Stack Overflow y yo, un novato en una ciudad con código que no conocía.
El caso simple se acababa de complicar. El GET al endpoint se transformó en una conexión directa a una base de datos que jamás había tocado. Pero, como todo en Blade Runner, nada es lo que parece…
Capítulo 3: Sin ORM, sin red de seguridad, sin nada
Lo primero que hice fue buscar la salida fácil. Si podía conectar Snowflake a través de un ORM, el problema se reducía a configurar un dialecto y seguir con mi vida. Así que empecé a revisar los sospechosos habituales.
User.findAll() y él lo convierte en SELECT * FROM users.Sequelize, el ORM que usaba en ese entonces, tenía soporte para Snowflake... pero marcado como experimental. Una etiqueta que en el mundo real significa: "ni lo intentes en productivo". Tocaba descartarlo.
TypeORM, Knex.js, Prisma... ninguno ofrecía soporte. Snowflake no era una base de datos lo suficientemente conocida como para que los ORM y query builders de Node.js le abrieran la puerta. Era como buscar un replicante en un registro que solo tenía humanos.
Sin ORM, sin query builder, la situación era clara: habría que hacer todo a mano: conexión manual, queries en SQL puro y transformaciones artesanales. El tipo de trabajo sucio que nadie documenta en los tutoriales bonitos, pero que mantiene las integraciones a flote en la vida real.
Me terminé el café de un solo sorbo y abrí la documentación oficial de Snowflake: Era hora de ensuciarse las manos.
Capítulo 4: Callbacks del pasado, replicantes que se niegan a morir
La documentación de Snowflake me llevó a su librería oficial para Node.js: el Snowflake SDK existía, por lo que podía hacer la conexión. Pero tenía un problema: estaba construida en otra época.
La librería no soportaba async/await. Cada operación, desde conectar hasta ejecutar una query, funcionaba exclusivamente con callbacks. En pleno 202X, con promesas y async/await como estándar en cualquier proyecto Node.js moderno, Snowflake me obligaba a volver al pasado.
Sacado desde la documentación oficial, y con un poquito de edición, la forma de realizar una conexión era la siguiente:
connection.connect((err, conn) => {
if (err) {
console.error(`Unable to connect: ${err.message}`);
return;
} else {
conn.execute({
sqlText: "SELECT * FROM replicants",
complete: (err, stmt, rows) => {
if (err) {
console.error("Error en la query:", err);
return;
}
console.log(rows); // Aquí está la data
}
});
}
});Si necesitabas encadenar varias operaciones, como conectar, ejecutar una query, procesar los resultados y cerrar la conexión, terminabas en el famoso callback hell: una pirámide de funciones anidadas donde el código crece hacia la derecha en lugar de hacia abajo, la legibilidad se desploma y un solo error de indentación te puede costar horas de depuración.
Eran replicantes del pasado: funcionales, resistentes, pero incompatibles con el mundo moderno. Y no podía simplemente retirarlos; los necesitaba vivos para completar el caso.
Capítulo 5: Creando un nuevo modelo, la clase Snowflake
Si el SDK no hablaba el idioma moderno, tocaba enseñarle.
La solución fue crear una clase wrapper que envolviera toda la lógica de callbacks del SDK y la expusiera como promesas. Una capa de syntactic sugar que tradujera el mundo antiguo de los callbacks y el async/await que el resto del proyecto necesitaba. Algo como esto:
class SnowflakeClient {
private connection: Connection;
constructor(private readonly config: SnowflakeConfig) {
this.connection = snowflake.createConnection(config);
}
connect(): Promise<void> {
return new Promise((resolve, reject) => {
this.connection.connect((err) => {
if (err) reject(err);
else resolve();
});
});
}
execute(sqlText: string): Promise<any[]> {
return new Promise((resolve, reject) => {
this.connection.execute({
sqlText,
complete: (err, _stmt, rows) => {
if (err) reject(err);
else resolve(rows || []);
}
});
});
}
disconnect(): Promise<void> {
return new Promise((resolve, reject) => {
this.connection.destroy((err) => {
if (err) reject(err);
else resolve();
});
});
}
}
La idea era sencilla: cada método del SDK que usaba callbacks se envolvía en una new Promise(). Si el callback reportaba un error, la promesa se rechazaba. Si todo salía bien, la promesa se resolvía. Así de limpio.
Con esta clase, el código del scheduler pasaba de una maraña de callbacks anidados a algo que cualquier dev del equipo podría leer sin necesitar un decodificador Voight-Kampff:
const client = new SnowflakeClient(config);
await client.connect();
const rows = await client.execute(
"SELECT * FROM replicants WHERE retired = false"
);
await client.disconnect();
Tres líneas. Sin pirámides. Sin indentación infinita. El replicante antiguo ahora hablaba un idioma moderno.
Capítulo 6: Queries a mano, el trabajo sucio sin query builder
Con la conexión resuelta, el siguiente problema estaba a la vuelta de la esquina: las queries.
Como mencioné antes, Knex.js no admitía Snowflake. No había un query builder con soporte oficial. Así que cada consulta se escribió a mano, en SQL puro, directamente como strings dentro del código.
SELECT * FROM users WHERE active = true, escribirías algo como db('users').where('active', true).select('*'). Esto reduce errores de sintaxis, facilita la composición dinámica de queries y mejora la legibilidad.Por esto, una consulta simple que se podía reducir a un par de lineas con un query builder, terminaba escrita a mano con un formato similar a este:
const query = `
SELECT
replicant_id,
model,
activation_date,
battery_life_hours,
retired
FROM nexus_db.public.replicants
WHERE retired = false
AND activation_date >= '2019-01-01'
`;
const rows = await client.execute(query);
En ese momento no conocía patrones de diseño que pudieran haber hecho esto más elegante. No sabía que existía la posibilidad de construir un query builder propio, o al menos un módulo que encapsulara las queries en funciones con nombres descriptivos. Simplemente escribí las consultas donde las necesitaba y seguí adelante.
¿Funcionaba? Sí. ¿Era lo más mantenible del mundo? No. Pero el reloj corría y Wallace Corp esperaba resultados, no arquitectura perfecta. Como diría el Capitán Julryant de la consultora: "Lo perfecto es enemigo de lo bueno"
Capítulo 7: La sobreingeniería del novato, value objects donde bastaba un mapper
Aquí viene la confesión. Con la conexión funcionando y las queries devolviendo datos, necesitaba transformar la información que venía de Snowflake al formato que la plataforma esperaba. Cambios de tipo, validaciones, conversiones de formato. Lo típico.
Lo que hice fue crear value objects para cada campo. Clases dedicadas que encapsulaban la validación del tipo de dato y la transformación en un solo lugar. Un ReplicantId que validaba que el ID fuera un string no vacío. Un BatteryLife que verificaba que las horas fueran un número positivo antes de convertirlas a días. Un ActivationDate que parseaba la fecha y la devolvía en el formato correcto.
class ReplicantId {
private readonly value: string;
constructor(raw: unknown) {
if (typeof raw !== "string" || raw.trim() === "") {
throw new Error("Invalid replicant ID");
}
this.value = raw.trim().toLowerCase();
}
toString(): string {
return this.value;
}
}
class BatteryLife {
private readonly days: number;
constructor(hours: unknown) {
if (typeof hours !== "number" || hours < 0) {
throw new Error("Invalid battery life");
}
this.days = Math.floor(hours / 24);
}
toDays(): number {
return this.days;
}
}
Cada campo tenía su propia clase. Cada clase validaba y transformaba. Y para construir el objeto final, había que instanciar cada value object, pasarle el dato crudo, y luego extraer el valor transformado. Esto funcionaba perfectamente, pero a su vez era totalmente innecesario para este caso.
Lo que realmente necesitaba era un mapper: una función simple que tomara el objeto de entrada y devolviera el objeto de salida con las transformaciones aplicadas. Sin clases extra. Sin instanciaciones. Sin la ceremonia de un value object para cada campo. Algo como esto:
function toReplicantOutput(row: SnowflakeRow): ReplicantOutput {
return {
replicantId: row.replicant_id.trim().toLowerCase(),
model: row.model,
activationDate: formatDate(row.activation_date),
batteryLifeDays: Math.floor(row.battery_life_hours / 24),
retired: row.retired === "true"
};
}Una función. Pura. Sin estado. Sin clases. Responsabilidades separadas de forma limpia.
Pero era novato. No conocía los patrones de diseño. La sobreingeniería es el precio que pagas por aprender, algo así como el "impuesto a la intuición" del desarrollo de software. Los value objects no rompieron nada; solo hicieron el desarrollo más extenso de lo que realmente era necesario, era el equivalente a "matar una mosca a cañonazos".
Capítulo 8: Un handler con demasiados recuerdos implantados
Pero había un problema más que, en ese momento, ni siquiera sabía que era un problema.
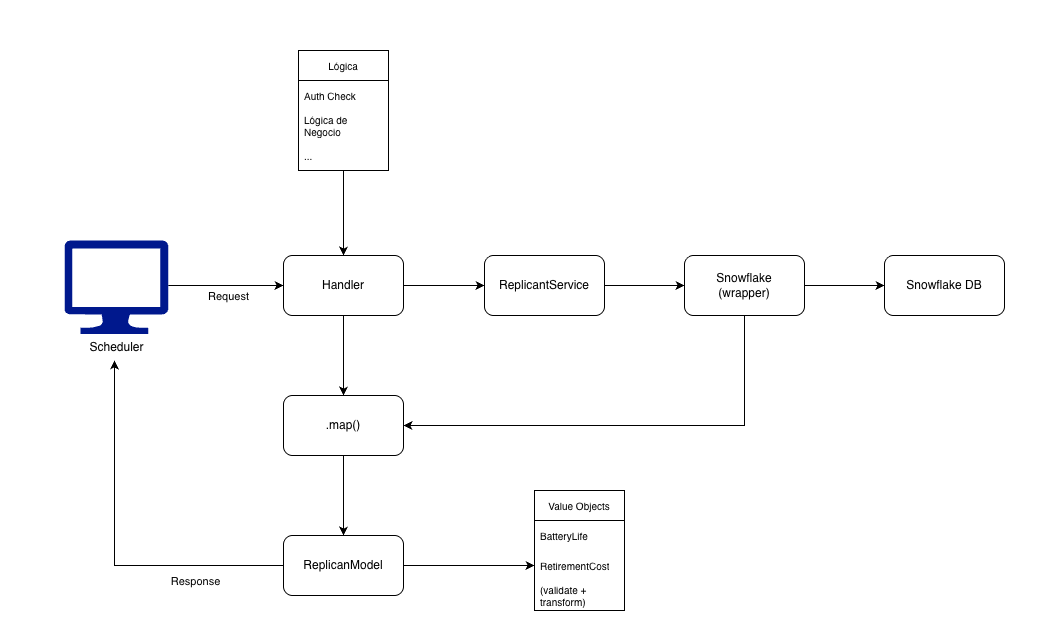
Como puedes ver en el diagrama, no conocía el Principio de Responsabilidad Única. No sabía que un handler debía limitarse a orquestar, no a ejecutar. Los middlewares eran un concepto que ni siquiera aparecía en mi radar. Así que hice lo que cualquier novato haría: puse todo donde sabía que funcionaba. Mi handler terminó con todo adentro: autenticación del token, instanciación del servicio, iteración de los datos, creación de modelos y hasta la separación de éxitos y errores.
El resultado es funcional, pero cada cambio significaba abrir esa función entera y rezar para no romper algo más. Hoy sé que cada una de esas responsabilidades debería vivir en su propia capa: los middlewares se encargan de la validación y la autenticación, el handler solo orquesta, el service contiene la lógica de negocio y el mapper transforma los datos.

Capítulo 9: Caso cerrado, el replicante entrega sus resultados
Con la clase wrapper lista, las queries escritas, los value objects haciendo su trabajo (excesivo pero funcional) y las transformaciones completas, el scheduler quedó operativo.
Una vez al día, como un reloj, el proceso se levantaba, se conectaba a Snowflake a través de la clase que construí, ejecutaba las consultas, transformaba los datos campo por campo, y los cargaba en la plataforma. Sin errores. Sin interrupciones. Sin que Wallace Corp tuviera la menor idea de que detrás de esa automatización había un novato que había aprendido a conectar una base de datos que nunca antes había visto, a envolver callbacks ancestrales en promesas modernas y a improvisar soluciones donde los frameworks se negaban a llegar.
El cliente quedó satisfecho. La data llegaba puntual. El proceso era estable. Para ellos, fue una integración más. Para mí, fue el primer caso que me enseñó que en el mundo del desarrollo, por más paradójico que parezca, escribir código es solo la punta del iceberg, el verdadero trabajo está en descifrar lo que te entregan y encontrar la forma de hacerlo funcionar con lo que tienes.
Capítulo 10: Lo que el no tan veterano le diría al novato
Si pudiera volver a Neovaldivia donde todo empezó, le dejaría una nota al novato que fui.
Le diría que empiece con un mapper, no con value objects. Que para transformaciones de datos en integraciones, una función pura es casi siempre suficiente. Los value objects son poderosos, pero no todo problema merece un cañonazo.
Le diría que el caso "simple" no existe. Que nunca confíe en un requerimiento que se ve demasiado limpio, porque siempre hay una sorpresa esperando al otro lado de la línea. Que se prepare para que el endpoint sea una base de datos, para que la API sea un blob, o para que el CSV tenga emojis. En este oficio, la paranoia es una virtud.
Y le diría que la IA no lo habría salvado de aprender. Hoy podría pedirle a un modelo que le genere el wrapper en segundos. Pero las decisiones de patrones, la separación de responsabilidades, el criterio de cuándo un value object es excesivo; eso no lo tomará a menos que se lo pidas explícitamente. Haber hecho este proyecto a mano me obligó a entender cómo funcionan las promesas por dentro, por qué los callbacks eran el estándar y qué significa realmente syntactic sugar. Ese conocimiento, a diferencia de los recuerdos implantados, es genuinamente mío.
Como en Blade Runner: todos los datos que transformé se perderán en el tiempo, como lágrimas en la lluvia... pero la lección de ese primer caso, esa permanece.
¿Cuál fue la integración más inesperada que te tocó resolver? Cada caso tiene su propio plot twist y me interesa conocer el tuyo.
Referencias:
Member discussion