Integración Replicante: caso Blob de Azure usando Repository+Factory Pattern en Serverless

Capítulo 1: El requerimiento, un encargo de TyrellCorp
Era un día cualquiera en la gran oficina remota, trabajando en lo de siempre y disfrutando mi espresso mañanero. Cuando de pronto llega una solicitud de un cliente con el que nunca he trabajado diciendo que está interesado en realizar un control de cambios para un flujo.
El cliente, a quien llamaremos TyrellCorp para mantener su privacidad (y yo mi trabajo) solicita lo siguiente: "Tenemos un formulario que, una vez respondido, realiza unos cálculos matemáticos y los almacena dentro de su plataforma. Lo que queremos ahora es que esa data también sea enviada automáticamente hacia nosotros cuando se cumplan ciertas condiciones".
Nos entregaron un endpoint y hasta especificaron el formato de la data. Esto suena a una integración común y corriente: tomas la data ya almacenada, la transformas por medio de Serverless y finalmente la envías a una API externa dada por el cliente.
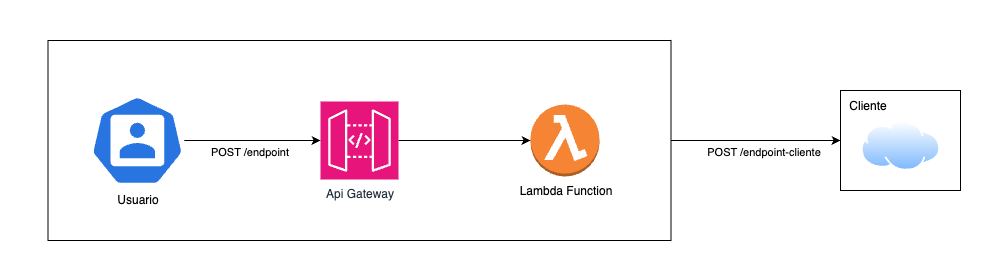
A simple vista, se podría deducir fácilmente que la arquitectura requerida es la que adjunto en la imagen. Pero, como todo en Blade Runner, nada es lo que parece…
Capítulo 2: El reto, un PUT que necesita el test Voight-Kampff
Decidido a enfrentar el desafío (aunque, siendo realista, no es que tuviera muchas opciones si quería preservar mi puesto como Blade Runner en la consultora). Me puse a revisar el endpoint que TyrellCorp nos había entregado, esperando encontrarme con una API RESTful lista para recibir la información de la forma más ortodoxa posible. Pero lo que me encontré fue algo diferente.
El endpoint era, en realidad, la puerta a un Blob de Azure. No aceptaba métodos clásicos de API REST, ni devolvía respuestas en JSON. Su trabajo era mucho más simple (y a la vez, mucho más complicado): tomaba cualquier cosa que le enviaras como body y la guardaba como un archivo, usando como nombre lo que le pusieras en la URL. ¿Quieres un Excel? Basta con enviar un PUT a /endpoint-cliente/archivo.xlsx y tendrás tu archivo, aunque, eso sí, será un Excel… corrupto, porque solo contendrá el texto plano que le enviaste, no un verdadero xlsx.
.txt hasta un Excel lleno de fórmulas, imágenes o cualquier archivo que se te ocurra. En servicios como Azure Blob Storage, cada archivo tiene una “dirección” única que puede ser sobrescrito, eliminado o consultado cuando quieras, pero a diferencia de una base de datos estructurada, el blob solo se encarga de guardar y entregar archivos enteros, sin preocuparse por columnas, filas o relaciones complicadas.Para más inri, solo tenía dos verbos: PUT para crear o modificar y GET para obtener. Si el archivo no existe, lo crea. Si ya existe, lo reemplaza. ¿Borrarlo? Basta con mandar un PUT con el body vacío y listo, archivo “borrado”.
Pude haber tomado esa llamada de red y pegarla directo en nuestro Serverless, usarla tal cual y olvidarme. Pero sabía que no podía dejar que los desarrolladores del futuro (o incluso mi yo del futuro) heredaran esa lógica extraña. ¿Qué pasaría si, años después, un nuevo dev quisiera cambiar la creación del archivo y se encontrara con un PUT multipropósito? Entender el trasfondo sería complicado, tanto como descifrar un test Voight-Kampff sin café.
Tocaba ponerse el abrigo de detective, centrar la mirada… y preparar un patrón de diseño que le diera sentido a este pequeño rincón cyberpunk de la nube.
Capítulo 3: La solución teórica, ¿Sueñan los blobs con lógica abstracta?
Aquí es donde los verdaderos Blade Runners del serverless entran en acción: Ocultar la lógica compleja del blob y entregarle a cualquier dev un set de métodos limpios, previsibles y desacoplados que pueda ser llamado desde afuera por medio de los típicos verbos: GET, POST, PATCH y DELETE. Así nació la idea de envolver toda la locura en el elegante abrigo del Repository Pattern.
El resultado terminó siendo tan ordenado como una ciudad bajo la lluvia ácida… pero sin replicantes ni recuerdos implantados (por ahora). No me considero el mejor diagramando, pero espero que se entienda con esta pequeña imagen:
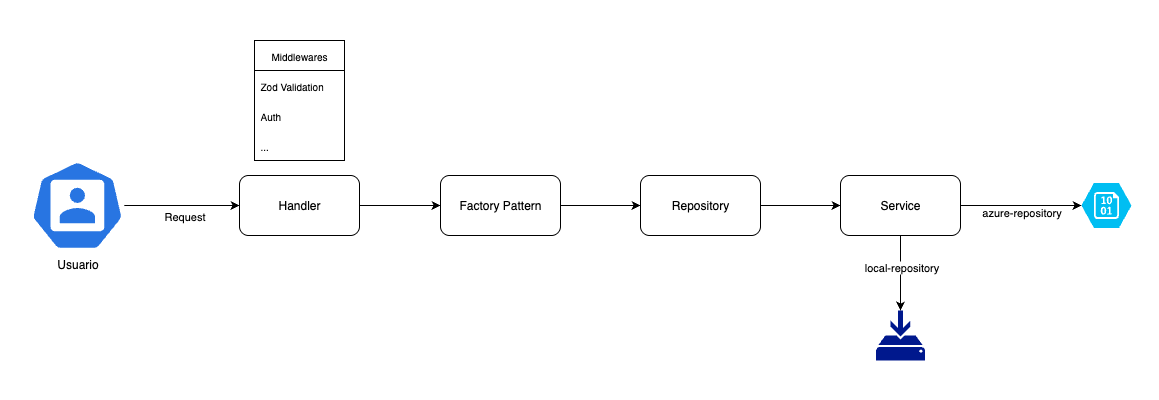
A nivel general, podemos explicarlo de la siguiente forma:
- El usuario envía una request a nuestro endpoint.
- La request pasa primero por el “check-in de seguridad”, donde nuestros middlewares se encargan de todo: validación de datos con Zod, autenticación del token y cualquier otra lógica transversal que tengamos en la fortaleza.
- Si todo está en orden, el handler entra en acción:
- Invoca el Factory, pasándole la variable de entorno (para saber en qué universo estamos parados: local, desarrollo o producción).
- El Factory le responde devolviéndole el Repository correspondiente para ese entorno.
- Con el repository listo, el handler crea una instancia del Service, pasándole el repository como parámetro.
- Ahora sí, el Service es quien se encarga de ejecutar la lógica del negocio: operaciones CRUD, transformaciones, cálculos… todo lo que TyrellCorp pidió, pero sin que nadie tenga que preocuparse por los detalles internos del blob de Azure ni los secretos del storage local.
- Para el resto del equipo, toda esta magia sucede tras bambalinas: interactúan con una interfaz uniforme y segura, mientras la lógica compleja queda elegantemente abstraída y lista para adaptarse a cualquier reto futuro.
Capítulo 4: Programando Replicantes, implementando el Repository Pattern en Serverless
Ahora que ya conoces la historia, es hora de pasar de la teoría al código. Aquí tienes una parte del desarrollo realizado, solo que más simplificado y cambiando datos específicos.
4.1 Entendiendo el requerimiento
Antes de ponernos manos a la obra, es clave revisar (a grandes rasgos) qué información tenemos y qué espera exactamente el cliente. Al analizar nuestro asset, notamos que el formulario realiza algunos cálculos y almacena la información con una estructura similar a la siguiente:
{
"replicant_id": "N7-239",
"model": "Nexus-6",
"activation_date": "1994-04-20T00:00:00.000Z",
"baterry_life_hours": 900000,
"retired": false
}Y el cliente busca almacenar su información en un json con el siguiente formato:
{
"ID": "n7_239",
"MODELO": "NEXUS_6",
"FECHA_ACTIVACION": "1995-04-20",
"BATERIA_EN_DIAS": "37500",
"ESTA_RETIRADO": "NO"
}¿Qué podemos extraer con esta revisión rápida?
- Las claves que serán almacenadas deben estar en español, con mayúsculas y usando guiones bajos.
replicant_idreemplaza los guiones por guiones bajos y las mayúsculas por minúsculas-
modelreemplazar sus guiones por guiones bajos y deja todo en mayúscula activation_datesolo almacena la fecha en formato YYYY-MM-DD.retired: convertir el booleano a "SÍ"/"NO" (como string).- Todos los valores deben ser almacenados como strings.
- Se espera que la batería esté en días, no en horas.
Este tipo de análisis previo es fundamental antes de cualquier integración, ya que asegura que la transformación de datos cumpla con las expectativas del cliente y previene dolores de cabeza futuros.
4.2 Validando la entrada con Zod y definiendo la interfaz de salida
Ahora necesitamos asegurarnos de que la documentación esté en regla. Aquí entra Zod, nuestro primer control migratorio: crearemos un esquema que valide que toda la data que llegue cumpla el formato que esperamos.

Para trabajar de manera cómoda (y mantener la cordura en el código), haremos un pequeño cambio de formato: transformaremos las claves de snake_case (replicant_id) a camelCase (replicantId).
export const ReplicantSchema = z.object({
replicantId: z.string(),
model: z.string(),
activationDate: z.string().datetime().transform(val => new Date(val)),
batteryLifeHours: z.number(),
retired: z.boolean()
}).strict()
export type Replicant = z.infer<typeof ReplicantSchema>Pero no termina ahí: para asegurarnos de que la información salga exactamente en el formato que espera el cliente, crearemos una interfaz que refleje el JSON final que irá al blob.
export interface ReplicantOutput {
ID: string;
MODELO: string;
FECHA_ACTIVACION: string;
BATERIA_EN_DIAS: string;
ESTA_RETIRADO: "SÍ" | "NO";
}Con esto, cada vez que toque enviar data al blob, Typescript nos avisará si falta alguna clave o si el formato no es el correcto.
En resumen: validamos la entrada con Zod, normalizamos para trabajar más fácil en el código, y garantizamos la salida correcta usando una interfaz TypeScript.
4.3 Definiendo la interfaz base para el Repository Pattern
Ya con la data de entrada y salida claras, toca dar el siguiente paso: crear la interfaz que define nuestro Repository. Esta interfaz es el contrato sagrado entre tu servicio y cualquier fuente de datos (sea un blob, base de datos, archivo local o una IA rebelde del 2049). Así, no importa qué tecnología esté debajo, tu aplicación siempre sabrá cómo interactuar con ella.
export interface ReplicantRepository<T> {
create(data: Replicant): Promise<T>; // Create
locate(id: string): Promise<T>; // Read
reprogram(id: string, data: Partial<Replicant>): Promise<T>; // Update
destroy(id: string): Promise<boolean>; // Delete
}El uso del genérico T es muy importante: significa que cada implementación del Repository puede decidir qué retornará exactamente, adaptándose a sus propias necesidades. Por ejemplo, podrías querer que tu implementación para MongoDB retorne solo el ID y el campo ESTA_RETIRADO, mientras que tu versión local puede devolver también información adicional como NOMBRE_ARCHIVO. Así, cada contexto puede definir el “tipo de respuesta” ideal sin forzar a todas las fuentes de datos a comportarse igual.
Por último, tanto el método create como reprogram reciben como input un objeto Replicant. Esto garantiza que siempre trabajaremos con la data ya validada y transformada, lista para enviarse tal cual el cliente la espera.
4.4 Implementando los repositories concretos
Ahora toca materializar la teoría en dos implementaciones concretas: una para guardar archivos localmente (usada para testear) y otra para subirlos a Azure Blob Storage. Así aseguramos que, tanto en pruebas como en producción, el proceso sea igual de sencillo… y predecible.
export class ReplicantLocalRepository implements ReplicantRepository<ReplicantOutput> {
async create(data: Replicant) {
// Aquí va la lógica para escribir en /tmp un fichero JSON
}
// Aquí van los demás métodos: locate, reprogram y destroy
}
export class ReplicantAzureRepository implements ReplicantRepository<ReplicantOutput> {
constructor(private readonly configFile: AzureConfig) {}
async create(data: Replicant) {
// Aquí va la llamada de red PUT a /endpoint-cliente/archivo.json
}
async locate(id: string){
// Aquí va la llamada de red GET a /endpoint-cliente/archivo.json
}
// Aquí van los demás métodos: reprogram y destroy
}En este caso, ambas implementaciones utilizan ReplicantOutput como tipo de retorno, ya que quiero poder comparar fácilmente lo que se escribe en local con lo que se subirá al blob. Sin embargo, si en algún momento necesitas transformar el input en un output totalmente distinto según el repositorio, basta con cambiar ese tipo: la interfaz genérica te lo permitirá hacer sin problemas.
Además, cualquier clase que implemente ReplicantRepository estará obligada a tener los cuatro métodos definidos (create, locate, reprogram y destroy). Esto asegura que, desde los servicios más arriba, todos los repositorios compartan la misma interfaz y los mismos nombres. Así, no importa si estás leyendo de un blob, una base de datos o el diario íntimo de Roy Batty: el resto de tu programa siempre sabrá cómo comunicarse de forma clara y consistente.
4.5: Transformando los datos de A a B
Hasta ahora, tenemos los repositories listos para recibir y devolver información… pero hay un detalle importante: todavía no existe una forma directa de convertir un objeto Replicant en su correspondiente ReplicantOutput. Aquí es donde entra en juego una herramienta clásica, pero a menudo subestimada: el mapper.
Replicant) y transformarlo en otro (ReplicantOutput). Su función es separar la estructura interna de tus datos de la forma en que los quieres exponer o persistir. De esta manera, tu lógica de negocio no se enreda con detalles de formato, y puedes adaptar o evolucionar tus modelos sin tener que reescribir todo tu código.Quizá pueda sonar algo complicado, pero en términos sencillos, es simplemente pasar un dato A a un dato B. En este caso, crearemos una pequeña función dentro del factory que nos sirva como mapper:
function replicantToReplicantOutputMapper(replicant: Replicant): ReplicantOutput{
return {
ID: slug(replicant.replicantId),
MODELO: slug(replicant.model).toUpperCase(),
FECHA_ACTIVACION: datetimeToDate(replicant.activationDate),
BATERIA_EN_DIAS: String(replicant.batteryLifeHours/24),
ESTA_RETIRADO: replicant.retired ? "SÍ" : "NO"
}
}Ahora, cada vez que guardemos datos desde el repository, simplemente llamamos a la función, la cuál nos permitirá pasar el objeto original por el mapper, y listo: todo sale en el formato que tu cliente (o tu blob) espera. En síntesis, con esto podremos pasar de Replicant a ReplicantOutput fácilmente
/mappers). Esto ayuda a reutilizarlo y mantener la lógica de transformación desacoplada del almacenamiento. Pero lo mantendremos así por simplicidad.4.6: Usar el repository en los services
Para mantener el principio de responsabilidad única, toda la lógica de negocio debe estar contenida en los servicios (services), no en los handlers ni en los controladores.
Los servicios reciben la instancia del repository mediante inyección de dependencias, lo que significa que pueden trabajar con cualquier implementación concreta (local, Azure, base de datos, etc.) sin que la lógica de negocio tenga que cambiar.
export class ReplicantService<T> {
constructor(private readonly replicantRepository: ReplicantRepository<T>) {}
async create(data: Replicant) {
return this.replicantRepository.create(data);
}
async findOne(id: string) {
return this.replicantRepository.locate(id);
}
async update(id: string, data: Partial<Replicant>) {
return this.replicantRepository.reprogram(id, data);
}
async delete(id: string) {
return this.replicantRepository.destroy(id);
}
}
4.7 Creando el Factory Pattern
Ahora, nos enfrentamos un pequeño problema. ¿Cómo puede saber nuestro código en qué momento usar un Repository específico de forma automática sin que debamos decírselo explícitamente?
Para esto necesitamos utilizar el clásico Factory Pattern: un patrón de diseño que permite instanciar dinámicamente la clase adecuada, manteniendo desacoplada la lógica de creación respecto al resto de la aplicación.
El objetivo de este factory es que, en tiempo de ejecución, si ejecutas el código en local, se utilice ReplicantLocalRepository para guardar archivos en /tmp y así poder testear tu lógica fácilmente. Pero si ejecutas en development o production, se instanciará ReplicantAzureRepository, que toma las variables de entorno necesarias para subir el archivo a Azure Blob Storage.
export function replicantRepositoryFactory(env: string){
if (env === 'local') return new ReplicantLocalRepository();
if (env === 'development' || env === 'production') return new ReplicantAzureRepository(azureHttpConfig);
throw new Error(`Unknown environment: ${env}`);
}¿Y si en el futuro el cliente decide que ya no quiere almacenar la información en un blob de Azure en producción y, en cambio, nos entrega credenciales para escribir directamente en una base de datos? No hay problema: solo tienes que crear un nuevo repository que implemente la interfaz ReplicantRepository y agregarlo a tu factory. Así, el resto del código sigue funcionando igual, sin importar qué tecnología esté por debajo; la lógica de negocio permanece totalmente desacoplada de la infraestructura.
4.8: Llama al service desde tus handlers
Llegamos al último eslabón de la cadena: el handler de Lambda. Aquí es donde orquestamos todo según el verbo HTTP, manteniendo la estructura limpia y desacoplada gracias a todo lo anterior.
const replicantRepository = replicantRepositoryFactory(process.env.NODE_ENV);
const handlerCreateReplicant = async (event) => {
const replicant = event.body
const replicantService = new ReplicantService(replicantRepository)
const replicantCreate = await replicantService.create(replicant)
return { statusCode: 201, body: JSON.stringify(replicantCreate) };
};
export const createReplicant = middy(handlerCreateReplicant)
.use(validateBody(ReplicantSchema))
¿Por qué es importante estructurarlo así?
- Desacoplamiento: Puedes cambiar la fuente de datos en cualquier momento (ideal para testing o cambios de infraestructura) sin tener que reescribir la lógica de los endpoints. ¿El cliente decide abandonar Azure Blob y mudarse a S3? Solo creas un nuevo repository, lo añades al factory, y el resto del código sigue igual.
- Validación temprana: El middleware de Zod con middy garantiza que sólo entra al handler data válida, lo que elimina la necesidad de validaciones manuales dentro de la lógica.
- Escalabilidad y mantenibilidad: Toda la arquitectura está pensada para escalar, ser probada y mantenida fácilmente. El factory se encarga de seleccionar el repository correcto al inicio, y ese mismo objeto es el que se utiliza a lo largo de todo el ciclo de vida de la request.
- Principio de responsabilidad única: Cada capa hace solo lo que le corresponde: el handler orquesta, el service maneja la lógica de negocio y el repository se encarga de la persistencia.
Capítulo 5: Evitando que horas de refactorización se pierdan en el tiempo… como lágrimas en la lluvia.
A veces el mundo real (o el digital) nos entrega “replicantes” que no calzan en los moldes clásicos. Un Blob que quiere ser API, un PUT que quiere ser POST, DELETE y PATCH al mismo tiempo…
Pero con patrones sólidos, validación estricta y un poco de ciencia ficción, logramos abstraer la complejidad y darle a cada endpoint su verdadero propósito, sin dejar que el caos gane la partida.
Como en Blade Runner: “Lo importante no es si los datos son reales o artificiales… lo importante es que tu integración siga funcionando, pase lo que pase.”
Referencias:


Member discussion